
WebRTC has been one of the most hot topics recently when it comes to Web technologies, it enables peer-to-peer(P2P) connectivity between browsers, which were originally designed as a platform for the client-server model and therefore, with a centralized resource lookup system in mind.
Goal#
The idea of moving from a centralized to a decentralized Resource Discovery in the browser was what brought me to start this research, to understand more how we can leverage the new P2P capabilities that WebRTC offers, in order to offload that load from central servers.
Current art on P2P algorithms (structured vs unstructured)#
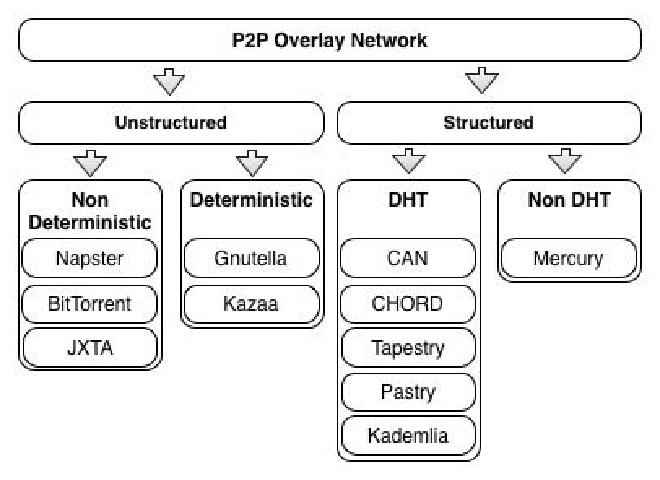
Efficient resource discovery mechanisms are fundamental for a decentralized system success, such as grid computing, cycle sharing or web application’s infrastructures. In a P2P network, peers churn rate can vary greatly, there are no ways to start new machines on demand during high periods of activity, the machines present are heterogeneous and so is their Internet connectivity, this creates a very unstable and unreliable environment, comparing to the distributed infrastructures we are used to deal inside data centers. To overcome these challenges, several researches have been made to optimize how data is organized across all the nodes, improving the performance, stability and the availability of resources. The several existing P2P Algorithms are typically divided in two categories in the literature: Unstructured or Structured.
Unstructured#
Unstructured P2P networks don’t require or define any constraints for data placement. Some of the most known are Napster, Kazaa and Gnutella for the file sharing capabilities. There is however a ‘caveat’ in the Unstructured networks, by not having an inherent way of indexing the data present in the network, performing a lookup results of the cost of asking several nodes the whereabouts of a specific file or chunk of the file (also known as flooding), creating a huge performance impact with an increasing number of nodes.
In order to calibrate the performance, Unstructured P2P networks offer several degrees of decentralization, one example is the evolution from Gnutella 0.4 to Gnutella 0.6(A, B), which added the concept of super nodes, entities responsible for storing the lookup tables(indexes) for the files stored in areas of the networkthey are responsible for, increasing the performance, but with the cost of adding centralized, single points of failure.
Unstructured networks are classified in two types: deterministic and non-deterministic, defining that in a deterministic system, we can calculate before hand the number of hops needed to perform a lookup, knowing the predefined bounds. File transfers are decentralized, but file lookup remains centralized, keeping the data for the lookup tables stored in one place, which can be gathered by one of two ways: (i) peers inform directly the index server the files they have; or (ii) the index server performs a crawling in the network, just like a common web search engine, this gives this network a complexity of O(1) to perform a search, however systems like Gnutella 0.6, which added the super node concept, remain non deterministic because it’s required to execute a query flood across all the super nodes to perform the search.
Structured with a Distributed Hash Table (DHT)#
Structured P2P networks have an implicit way of allocating nodes for files and replicas storage, without the need of having any specie of centralized system for indexing, this is done by taking the properties of a cryptographic hash function(A, B, C), such as SHA-1, which applies a transformation to any set of data with a uniform distribution of possibilities, creating an index with O(log(n)) peers, where the hash of the file represents the key and gives a reference to the position of the file in the network.
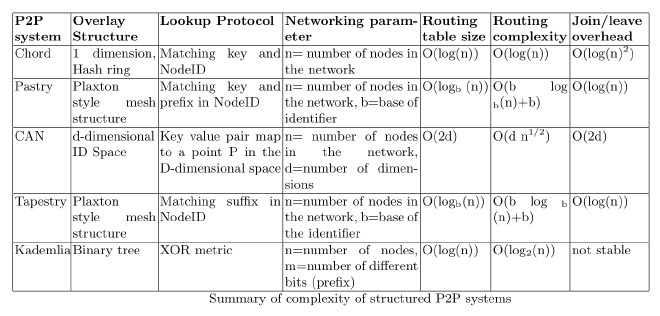
DHT’s such as Chord, Pastry and Tapestry, use a similar strategy, mapping the nodes present in the network inside an hash ring, where each node becomes responsible for a segment of the hash ring, leveraging the responsibility to forward messages across the ring to its `fingers’(nodes that it knows the whereabouts). Kademlia organizes its nodes in a balanced binary tree, using XOR as a metric to perform the searches, while CAN introduced a several dimension indexing system, in which a new node joining the network, will split the space with another node that has the most to load/responsability.
DHT Structured P2P networks have identifiable issues, they result from the trade-off of not having an centralized infrastructure, responsible for railing new nodes or storing the meta-data, these are: (i) generation of unique node-ids is not easy achievable, we need always to verify that the node-id generated does not exist, in order to avoid collisions; (ii) the routing table is partitioned across the nodes, increasing the lookup time as it scales.
The table below presents a synthesized view of each structured P2P algorithm with regards to their complexity.
structured without a DHT#
Mercury, a structured P2P network that uses a non DHT model, was designed to enable range queries over several attributes that data can be dimensioned on, which is desired on searches over keywords in several documents of text. Mercury design offers an explicit load balancing without the use of cryptographic hash functions, organizing the data in a circular way, named `attribute hubs’.
What’s current available on the WebRTC space (on the resource discovery area)#
There has been several successful attempts to leverage the ability for resource sharing through WebRTC, creating a new generation of Content Delivery Networks (CDN), offloading it from servers. Some of the most known systems are: PeerCDN, StreamRoot (Production Systems) and Maygh (Academic Research).
These services provide, however, a resource discovery lookup system through a centralized server, which contains information of each fragment that every client contains, meaning that a client will always have to contact the server first in order to fetch data from one of the other peers.
webrtc-ring#
webrtc-ring was created with the goal enable resource discovery from a browser, avoiding to hit a server to identify where the resource is located. The logic is encapsulated in a simple Node.js module, webrtc-ring and since we are talking about WebRTC, proper signaling is also provided for this case scenario, through webrtc-ring-signaling-server.
webrtc-ring offers a convenient manner to propagate messages in a P2P WebRTC network, delivering the respective message to the Node responsible for the ID range of the message, it does not handle however, storing of any data delivered, that is the developer responsibility to decide what to do with that information.
API#
The updated API documentation can be found in the official repository for this project: https://github.com/diasdavid/webrtc-ring
Structure#
Nodes (or peers), are organized in a hash ring, similar to Chord, with fundamental difference that they are only aware of the node that is their successor, this creates a tradeoff comparing to Chord, requiring a greater number of hops for a message to reach its destination, but the number of messages for a node join/leave is greatly reduced to always 2.
So, in essence we have the following properties:
- overlay structure - 1 dimension Hash Ring
- lookup protocol - Matching key and NodeID
- network parameters - Number of Nodes in the network
- routing table size - 1
- routing complexity - O(log(N))
- join/leave overhead - 2
Tests and results#
In order to evaluate the feasability and efficiency of webrtc-ring for a possible real world scenario, a benchmark was performed using ray-tracing algorithm (simple-raytracer). The goal in mind was to compare a single browser job to several browsers running tasks (computing units) of the same job independently, and infer if we have a speed up that results from task distribution and parallel execution without compromising its efficiency due to message routing over the webrtc-ring overlay network.
One aspect observed is that the overall efficiency can be influenced by adjusting how much resources we are going to take from the network to process the job, in this case, how much browsers are going to contribute. One another aspect that also influences the results is adjusting how much fine-grained each task it will be: the smaller the computation unit, the more we can distribute tasks through the network, with a natural trade-off of adding more task generation and messaging overhead, with diminishing returns when more and more, and smaller tasks are created.
The ray-tracing job used to give a rough benchmark takes around 24ms to complete if executed sequentially by a single node/browser.
For the tests, only a single machine was used in two different scenarios, one with induced expected network delay (~1ms to ~2ms for each hop) and another without.
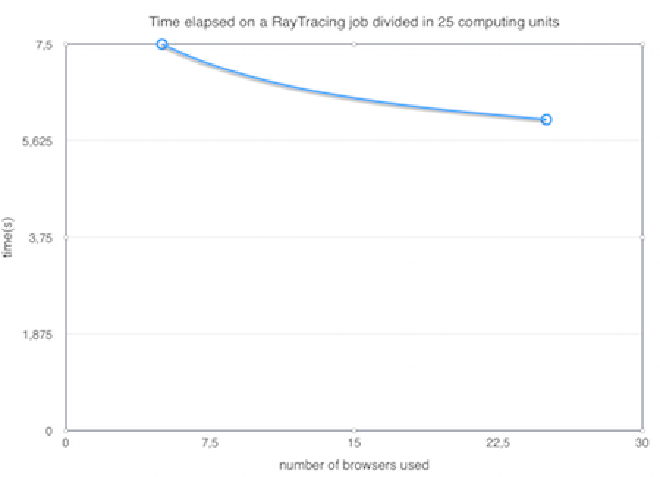
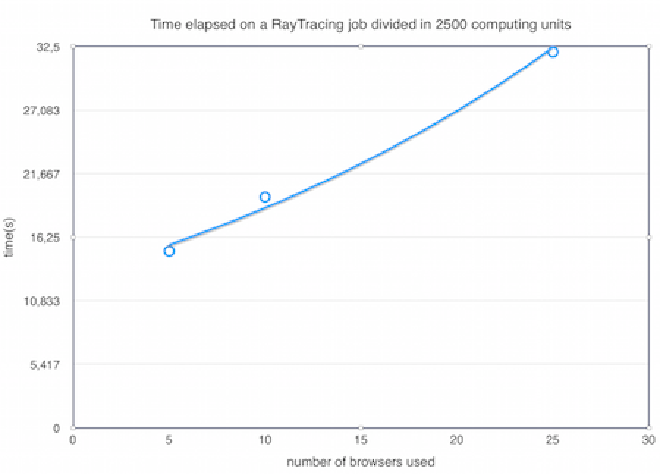
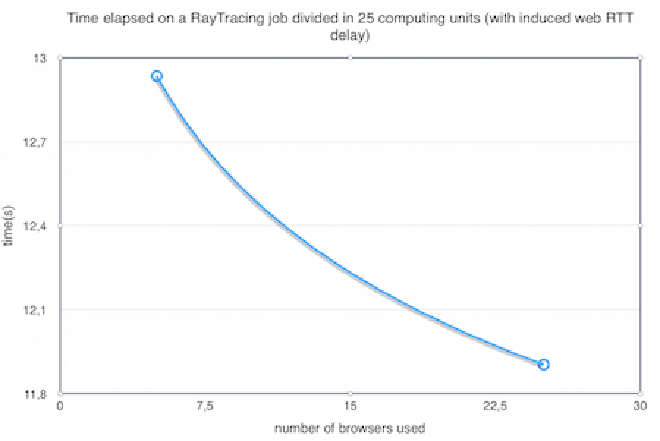
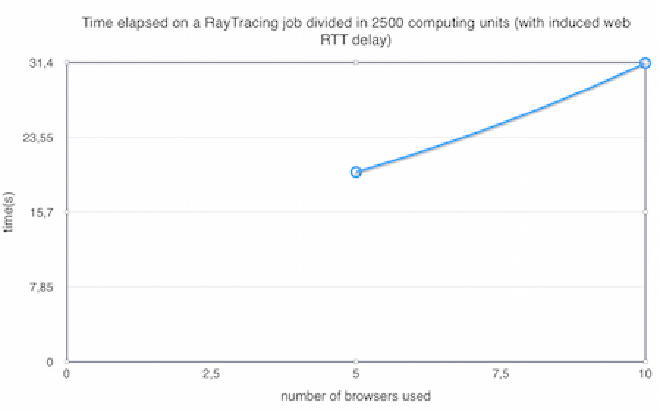
One interesting fact is that a much better performance was obtained by reducing the granularity of the ray-tracing job. This happens due to two factors: a) since there are a lower number of tasks to be run by other browsers, the message routing overhead gets reduced; b) the second factor is that since this system was tested using a single machine and a networked simulated delay, when the number of tasks is too large, the workers in the browser are in fact competing for CPU resources (to execute tasks and to forward messages among them). This creates a scenario, where more nodes/workers actually make the system slower, since this is a much more strict and resource constrained scenario, than a real example with browsers executing in different machines.
In a real world example, the actual execution time would be bounded by:
jobTime_A = slowestDelayFromResourceDiscovery +
timeOfExecutingSlowestTask +
slowestDelayFromResultReply;
with full parallelism, where in the test scenario we have:
jobTime_B = sum(DelayFromResourceDiscovery) +
TimeOfExecuting_N_Tasks_on_M_Resources +
sum(DelayFromResultReply);
With more browsers from more machines, the total execution time (makespan) of a ray-tracing job would be closer to that described by Equation A.
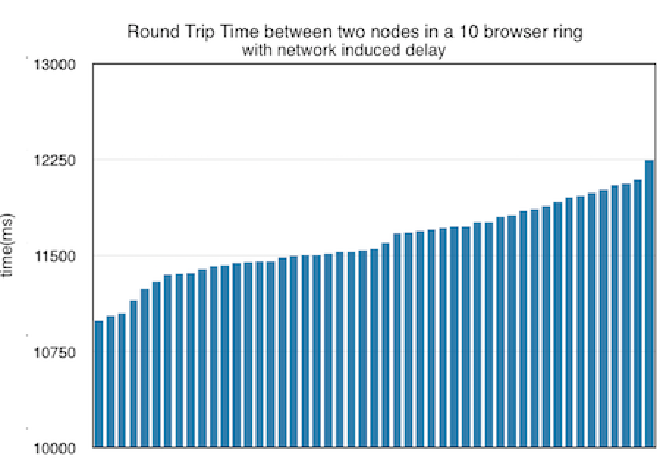
Another interesting analysis is the RTT between any of two nodes, shown in the image below. This is influenced by the current implementation where each node only knows its successor, causing a message that is sent and replied back will have to cross every single node available in the network at a given time.
Conclusions and future work#
It was observed that opening 25 browser tab instances, creating an individual node in each, which requires 2 WebRTC data channels, one for the predecessor and another for the successor, caused the browser to become incredibly slow and unresponsive, this has led me to understand that even though there were several things competing for machine resources, implementing a full Chord algorithm might be unpractical, since it requires 160 connections, or so called fingers, to another peers, which would result in ~320 data channels per each node.
Reducing the number of hops in the ring is also important to reduce messaging overhead and delay. Currently, there is address space for 2^160 peers available, creating a message routing worst case scenario of 2^160 - 1 hops for a message to reach to the node with a nodeID previous to the current Node in the ring.
One of the questions I’m currently presented is to identify if there would be the consequences from reducing the number of bits available per nodeID (currently 160) and therefore, reducing the number of fingers needed to implement a version more close to the Chord routing algorithm, or if there is a way to adjust the size of the address space depending on the service needs, creating smaller rings that are easier to manipulate and propagate messages.
There are also some other performance bottlenecks noticed that arise from the single threaded nature of JavaScript. These aspects were considered in our performance evaluation, such as:
- item logging - Since V8 runs in a single thread, any synchronous operation will block the event loop and add delay to the whole processing, although these logs are essential for us to assess the efficiency of the infrastructure, they are not vital to the job.
- delay added - One technique used to simulate the network delay is to use the
setTimeoutnative function of V8’s JavaScript implementation, since this function is unable to receive floating millisecond values. Moreover, sincesetTimeoutdoes not necessarily guarantee that the function will be executed in X amount of milliseconds, due to the nature of the event loop, there is always an extra delay added implicitly to the operation in the order of 1 to 3 ms. - tasks can not be sent in parallel - A node has to send each individual computing unit sequentially and independently, meaning that if job is divided into 2000 for e.g, each task will have to wait for the previous to be sent.
All of these concerns were studied and will be tackled in future work.